 What people commonly refer to as the Web is just scratching the surface. Beneath that is a huge, for the most part unchartered, ocean known as the Deep Web.
What people commonly refer to as the Web is just scratching the surface. Beneath that is a huge, for the most part unchartered, ocean known as the Deep Web.
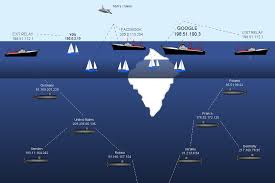
The Deep Web’s size is not easy to calculate. However, researchers in universities say the Web that is well known – Wikipedia, Facebook and new – is equal to less than 1% of the complete World Wide Web.
When surfing the Web, most people are just on the very periphery of what is available. Diving below that surface will open up trillions and trillions of different pages, an actual unfathomable number that the majority of people have not ever seen. The pages are everything from selling parts of the human body, which is illegal to boring reams of statistics.
What they are not capturing are the dynamic pages, like ones that are generated when asking a question to an online database.
Typically the web crawler cannot follow the links into the deeper content beneath the search box, said an analyst that explored the Deep Web at one time.
Google as well as others do not capture the pages behind the private networks and standalone pages that then connect to nothing more.
The majority of the Deep Web is a holder of pages with very important information. In 2001, a report said that it estimates that 54% of all websites are databases. The largest in the world include NASA, the U.S. National and Atmospheric Administration, the Patent and Trademark Office as well as the SEC’s EDGAR search system.
Those pages are all public. After that are pages that companies keep private that charge to enter them such as documents by the government on Westlaw and LexisNexis or Elsevier an academic journal.
About 13% of the total pages are hidden away since they are only on Intranet.
Tor is the deepest of all the Deep Web with secret websites ending with .onion, which require special software to gain access.